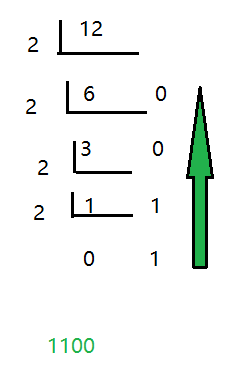第一章 Java语言概述 常用dos命令
操作
说明
盘符名称:
盘符切换。E:回车,表示切换到E盘。
dir
列出当前目录下的文件以及文件夹
cd 目录
进入指定单级目录。
cd 目录1\目录2\…
进入指定多级目录。cd atguigu\JavaSE
cd ..
回退到上一级目录。
cd \ 或 cd /
回退到盘符目录。
操作
说明
md 文件目录名
创建指定的文件目录。
rd 文件目录名
删除指定的文件目录(如文件目录内有数据,删除失败)
操作
说明
cls
清屏。
exit
退出命令提示符窗口。
← →
移动光标
↑ ↓
调阅历史操作命令
Delete和Backspace
del 文件名.后缀名 del *.后缀名
jvm和跨平台 JVM功能说明 JVM (Java Virtual Machine ,Java虚拟机):是一个虚拟的计算机,是Java程序的运行环境。JVM具有指令集并使用不同的存储区域,负责执行指令,管理数据、内存、寄存器。
功能1:实现Java程序的跨平台性 我们编写的Java代码,都运行在JVM 之上。正是因为有了JVM,才使得Java程序具备了跨平台性。
功能2:自动内存管理(内存分配、内存回收)
Java程序在运行过程中,涉及到运算的数据的分配、存储等都由JVM来完成
Java消除了程序员回收无用内存空间的职责。提供了一种系统级线程跟踪存储空间的分配情况,在内存空间达到相应阈值时,检查并释放可被释放的存储器空间。
GC的自动回收,提高了内存空间的利用效率,也提高了编程人员的效率,很大程度上减少了因为没有释放空间而导致的内存泄漏。
JDK和JRE
JDK (Java Development Kit):是Java程序开发工具包,包含JRE 和开发人员使用的工具。**JRE ** (Java Runtime Environment) :是Java程序的运行时环境,包含JVM 和运行时所需要的核心类库。
小结:
JDK = JRE + 开发工具集(例如Javac编译工具等)
JRE = JVM + Java SE标准类库
注释
小结:
1.一个java文件只写一个class,而且带public
2.类名和java文件名保持一致
3.main方法写在带public的类中
println和print区别
相同点:都是输出语句
快捷键
复制当前行 ctrl+d
一次操作多行:
	a.预留出足够的空间
	b.按住alt不放,鼠标往下拉,此时发现光标变长了
sout: 打印
开发体验:HelloWorld(掌握) JDK安装完毕,我们就可以开发第一个Java程序了,习惯性的称为:HelloWorld。
开发步骤 Java程序开发三步骤:编写 、编译 、运行 。
将 Java 代码编写 到扩展名为 .java 的源文件中
通过 javac.exe 命令对该 java 文件进行编译 ,生成一个或多个字节码文件
通过 java.exe 命令对生成的 class 文件进行运行
编写 (1)在目录下新建文本文件,完整的文件名修改为HelloWorld.java,其中文件名为HelloWorld,后缀名必须为.java。
(2)用记事本或editplus等文本编辑器打开(虽然记事本也可以,但是没有关键字颜色标识,不利于初学者学习)
(3)在文件中输入如下代码,并且保存:
1 2 3 4 5 class HelloChina { public static void main (String[] args) { System.out.println("HelloWorld!!" ); } }
友情提示1:每个字母和符号必须与示例代码一模一样,包括大小写在内。
第一个HelloWord 源程序就编写完成了,但是这个文件是程序员编写的,JVM是看不懂的,也就不能运行,因此我们必须将编写好的Java源文件 编译成JVM可以看懂的字节码文件 ,也就是.class文件。
编译 命令:
举例:
编译成功后,命令行没有任何提示。打开D:\JavaSE\chapter01目录,发现产生了一个新的文件 HelloChina.class,该文件就是编译后的文件,是Java的可运行文件,称为字节码文件 ,有了字节码文件,就可以运行程序了。
运行 在DOS命令行中,在字节码文件目录下,使用java 命令进行运行。
命令:
主类是指包含main方法的类,main方法是Java程序的入口:
1 2 3 public static void main (String[] args) { }
举例:
错误演示:
java HelloChina.class
字符编码问题 当cmd命令行窗口的字符编码与.java源文件的字符编码不一致,如何解决?
在使用javac命令式,可以指定源文件的字符编码
1 javac -encoding utf-8 Review01.java
第二章 变量_数据类型转换 常量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 1. 概述:在代码的运行过程中,值不会发生改变的数据2. 分类: 整数常量:所有整数 小数常量:所有带小数点的 2.5 1.5 2.0 字符常量:带单引号的 '' 单引号中必须有且只能有一个内容 '1' (算) '11' (不算) '' (不算) 'a1' (不算) ' ' (算) ' ' (两个空格不算) '写一个tab键' (算) 字符串常量:带双引号的 "" 双引号中内容随意 "" "helloworld" 布尔常量:true (真) false (假) -> 这两个单词不要加双引号 "true" (这样写属于字符串,不属于布尔常量) 空常量:null 代表的是数据不存在
变量
数据类型
关键字
内存占用
取值范围
字节型
byte
1个字节
-128 至 127 定义byte变量时超出范围,废了
短整型
short
2个字节
-32768 至 32767
整型
int(默认)
4个字节
-2^31^ 至 2^31^-1 正负21个亿<br>-2147483648——2147483647
长整型
long
8个字节
-2^63^ 至 2^63^-1 19位数字<br>-9223372036854775808到9223372036854775807
单精度浮点数
float
4个字节
1.4013E-45 至 3.4028E+38
双精度浮点数
double(默认)
8个字节
4.9E-324 至 1.7977E+308
字符型
char
2个字节
0 至 2^16^-1
布尔类型
boolean
1个字节
true,false(可以做判断条件使用)
变量的介绍以及使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 1. 变量的数据类型: 基本数据类型:4 类8 种 整型:byte short int long 浮点型:float double 字符型:char 布尔型:boolean 引用数据类型: 类 数组 接口 枚举 注解 2. 概述:在代码的运行过程中,值会随着不同的情况而随时发生改变的数据 3. 作用:一次接收一个数据 将来定义一个变量,接收一个值,后续可能会根据不同的情况对此值进行修改,此时可以用变量 4. 定义: a.数据类型 变量名 = 值; b.数据类型 变量名; 变量名 = 值; c.连续定义三个相同类型的变量 数据类型 变量名1 ,变量名2 ,变量名3 ; 变量名1 = 值; 变量名2 = 值; 变量名3 = 值; 比如:int i,j,k; i = 10 ; j = 20 ; k = 30 ; 数据类型 变量名1 = 值,变量名2 = 值,变量名3 = 值; 比如: int i = 10 ,j = 20 ,k = 30 ; 正确读法:先看等号右边的,再看等号左边的 -> 将等号右边的数据赋值给等号左边的变量 哪怕等号右边有运算,我们都得先将等号右边的运算算出一个值来,最后赋值给等号左边的变量 5. 注意: a.字符串不属于基本数据类型,属于引用数据类型,用String表示 String是一个类,只不过字符串在定义的时候可以和基本数据类型格式一样 6. float 和double 的区别: a.float 的小数位只有23 位二进制,能表示的最大十进制为2 的23 次方(8388608 ),是7 位数,所以float 型代表的小数,小数位能表示7 位 b.double 的小数位只有52 位二进制,能表示的最大十进制为(4 503 599 627 370 496 ),是16 位数,所以double 型代表的小数,小数位能表示出16 位 7. 切记:将来开发不要用float 或者double 直接参与运算,因为直接参与运算会有精度损失问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 public class Demo03Var { public static void main (String[] args) { byte num1 = 100 ; System.out.println(num1); short num2 = 1000 ; num2 = 1001 ; System.out.println(num2); int num3 = 10000 ; num3 = 1 ; System.out.println(num3); long num4 = 10L ; System.out.println(num4); float num5 = 2.5F ; System.out.println(num5); double num6 = 2.5 ; System.out.println(num6); char num7 = 'A' ; System.out.println(num7); boolean num8 = true ; boolean num9 = false ; num8 = num9; System.out.println(num8); String name = "金莲" ; System.out.println(name); } }
变量使用时的注意事项
1 .变量不初始化(第一次赋值)不能直接使用
2.在同一个作用域(一对大括号就是一个作用域)中不能定义重名的变量
3.不同作用域中的数据尽量不要随意互相访问 
	 在小作用域中能直接访问大作用域中的变量 
	 在大作用域中不能直接访问小作用域中的变量
标识符 1.概述:咱们给类,方法,变量取的名字
	b.软性建议(可遵守可不遵守,但是建议遵守)
数据类型转换 1 2 3 4 5 6 7 8 9 10 11 12 13 14 1. 什么时候发生类型转换: a.等号左右两边类型不一致 b.不同类型的数据做运算 2. 分类: a.自动类型转换 将取值范围小的数据类型赋值给取值范围大的数据类型 -> 小自动转大 取值范围小的数据类型和取值范围大的数据类型数据做运算 -> 小自动转大 b.强制类型转换 当将取值范围大的数据类型赋值给取值范围小的数据类型 -> 需要强转 3. 基本类型中按照取值范围从小到大排序: byte ,short ,char -> int -> long -> float -> double
自动类型转换 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class Demo09DataType { public static void main (String[] args) { long num1 = 100 ; System.out.println(num1); int i = 10 ; double b = 2.5 ; double sum = i+b; System.out.println(sum); } }
强制类型转换 如何强转?
取值范围小的数据类型 变量名 = (取值范围小的数据类型)取值范围大的数据类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class Demo10DataType { public static void main (String[] args) { float num1 = 2.5F ; System.out.println(num1); } }
强转的注意事项 1 2 3 4 5 6 7 1. 不要随意写成强转的格式,因为会有精度损失问题以及数据溢出现象,除非没有办法2. byte ,short 定义的时候如果等号右边是整数常量,如果不超出byte 和short 的范围,不需要我们自己强转,jvm自动转型 byte ,short 如果等号右边有变量参与,byte 和short 自动提升为int ,然后结果再次赋值给byte 或者short 的变量,需要我们自己手动强转 3. char 类型数据如果参与运算,会自动提升为int 型,如果char 类型的字符提升为int 型会去ASCII码表(美国标准交换代码)范围内去查询字符对应的int 值,如果在ASCII码表范围内没有对应的int 值,回去unicode码表(万国码)中找
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public class Demo11DataType { public static void main (String[] args) { int i = (int )2.9 ; System.out.println(i); int j = (int )10000000000L ; System.out.println(j); System.out.println("=========================" ); byte b = 10 ; System.out.println(b); b = (byte )(b+1 ); System.out.println(b); System.out.println("=========================" ); char c = '中' ; System.out.println(c+0 ); } }
进制的转换 十进制转二进制
辗转相除法 -> 循环除以2,取余数
二进制转十进制
8421规则
二进制转八进制
将二进制数分开 (3位为一组),不够的前面补0
二进制转换为十六进制
将二进制数分组-> 4位为一组
位运算符
& | ^:
1、这三个符号既可以在位运算中也可以在逻辑运算中
2、区别:左右两侧是数字,则是位运算;两侧是boolean,则是逻辑运算
符号
说明
&
1.单与,如果前后都是布尔型,有假则假,但是如果符号前为false,符号后的判断会继续执行
&&
1.双与,有假则假,但是有短路效果,如果符号前为false,符号后的判断就不会执行了
|
1.单或,如果前后都是布尔型,有真则真,但是如果符号前为true,符号后的判断会继续执行
||
1.双或,有真则真,但是有短路效果,如果符号前为true,符号后的判断就不会执行了
位运算符
符号解释
&
有假则假
|
有真则真
~
取反
^
符号前后结果一样为false,不一样为true
<<
左移运算符
>>
右移运算符
>>>
无符号右移运算符
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 1. 符号的介绍: a. &(与) -> 有假则假 b. |(或) -> 有真则真 c. ~(非) -> 取反 d. ^(异或) -> 符号前后结果一样为false ,不一样为true true ^ true -> false false ^ false -> false true ^ false -> true false ^ true -> true 2. 1 代表true 0 代表false 3. 我们要知道计算机在存储数据的时候都是存储的数据的补码,计算也是用的数据的补码 但是我们最终看到的结果是原码换算出来的 原码 反码 补码 4. 正数二进制最高位为0 ; 负数二进制最高位为1 5. 如果是正数 原码 反码 补码 一致 比如:5 的原码 反码 补码一致: 0000 0000 0000 0000 0000 0000 0000 0101 -> 因为是正数,二进制最高位为0 如果是负数,原码 反码 补码不一样了 反码是原码的基础上最高位不变,剩下的0 和1 互换 补码是在反码的基础上+1 比如:-9 (补成32 个数字) 原码: 1000 0000 0000 0000 0000 0000 0000 1001 反码: 1111 1111 1111 1111 1111 1111 1111 0110 补码: 1111 1111 1111 1111 1111 1111 1111 0111
注意:以数据的==补码==进行计算
左移:<< 运算规则 :左移几位就相当于乘以2的几次方
注意: 当左移的位数n超过该数据类型的总位数时,相当于左移(n-总位数)位
1 2 3 4 5 2 <<2 结果等于8 快速算法: 2 *(2 的2 次方) -2 <<2 等于-8 快速算法: -2 *(2 的2 次方)
右移:>> 快速运算:类似于除以2的n次,如果不能整除,向下取整
1 2 3 4 5 9 >>2 等于2 快速算法: 9 除以(2 的2 次方) -9 >>2 等于-3 快速算法: -9 除以(2 的2 次方)
==注意:负数右移,左边补1==
无符号右移:>>> 运算规则:往右移动后,左边空出来的位直接补0,不管最高位是0还是1空出来的都拿0补
正数:和右移一样
负数:右边移出去几位,左边补几个0,结果变为正数
笔试题: 8>>>32位 -> 相当于没有移动还是8
8>>>34位 -> 相当于往右移动2位
按位与:& 小技巧:将0看成为false 将1看成true
运算规则:对应位都是1才为1,相当于符号左右两边都为true,结果才为true
按位或:| 运算规则:对应位只要有1即为1,相当于符号前后只要有一个为true,结果就是true
1|1 结果1
1|0 结果1
0|1 结果1
0|0 结果0
按位异或:^ 1^1 结果为0 false
1^0 结果为1 true
0^1 结果为1 true
0^0 结果0 false
按位取反:~ 运算规则:~0就是1
\~1就是0
第三章 运算符 IDEA的使用
1.生成main方法:输入main -> 回车
2.生成输出语句:sout -> 回车
3.将变量名放到输出语句中:
a.变量名.sout
b.变量名.soutv -> 带字符串平拼接格式的输出方式-> 输出格式好看
快捷键
快捷键
功能
Alt+Enter导入包,自动修正代码(重中之重)
Ctrl+Y删除光标所在行
Ctrl+D复制光标所在行的内容,插入光标位置下面
Ctrl+Alt+L格式化代码
Ctrl+/单行注释
Ctrl+Shift+/选中代码注释,多行注释,再按取消注释
Alt+Shift+上下箭头移动当前代码行
出现的问题 1 2 3 4 5 6 7 8 9 10 1. 在运行代码时会出现"找不到对应的发行源" 或者"不支持发行版本" 或者"无效的发行源版本" ,证明本地jdk版本和idea中的language level不匹配 所以要匹配版本 file->project Structure->点击project->引入本地jdk->project level选择对应的版本 2. 没有out路径的问题 out路径是专门存放idea自动编译生成的.class文件的 所以需要指明out路径 3. src是灰色的,对着src,右键,选项中没有java class或者package 4. 刚使用,jdk没有配置
1.算数运算符
符号
说明
+
加法
-
减法
*
乘法
/
除法
%
模,取余数部分
1.2.自增自减运算符(也算算数运算符的一种) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 1. 格式: 变量++ -> 后自加 ++变量 -> 前自加 变量-- -> 后自减 --变量 -> 前自减 自增和自减只变化1 2. 使用: a.单独使用: ++ -- 单独为一句,没有和其他的语句掺和使用 i++; 符号前在在后都是先运算 b.混合使用: ++ -- 和其他的语句掺和使用了(比如:输出语句,赋值语句) 符号在前:先运算,在使用运算后的值 符号在后:先使用原值,使用完毕之后,自身再运算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package com.msl.calc;public class demo01 { public static void main (String[] args) { int a = 1 ; ++a; System.out.println("a = " + a); System.out.println("===========================" ); int i = 10 ; int result01 = i++; System.out.println("result01 = " + result01); System.out.println("i = " + i); System.out.println("===========================" ); int j = 10 ; int result02 = ++j; System.out.println("result02 = " + result02); System.out.println("j = " + j); } }
2.赋值运算符 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1. 基本赋值运算符: = -> 先看等号右边的,再将右边的数据赋值给等号左边的变量 2. 复合赋值运算符: +=: int i = 10 ; i+=2 -> i = i+2 -= *= /= : 取整数部分 %= : 取余数部分 3. 注意:byte short 遇到复合赋值运算符,jvm会自动转型
3.关系运算符(比较运算符) 1 2 1. 结果:boolean 型 -> 要么是true ,要么是false 2. 作用:做条件判断使用
符号
说明
==
如果符号前后相等为true;否则为false
>
如果符号前的数据大于符号后的数据为true,否则为false
<
如果符号前的数据小于符号后的数据为true,否则为false
>=
如果符号前的数据大于或者等于符号后的数据为true,否则为false
<=
如果符号前的数据小于或者等于符号后的数据为true,否则为false
!=
如果符号前后不相等为true;否则为false
4.逻辑运算符 1 2 1. 作用:连接多个boolean 结果的2. 结果:boolean 型结果
符号
说明
&&(与,并且)
有假则假,符号前后有一个结果为false,整体就是false
||(或者)
有真则真,符号前后有一个结果为true,整体就是true
!(非,取反)
不是true,就是false;不是false,就是true
^(异或)
符号前后结果一样为false;不一样为true
符号
说明
&
1.单与,如果前后都是布尔型,有假则假,但是如果符号前为false,符号后的判断会继续执行
&&
1.双与,有假则假,但是有短路效果,如果符号前为false,符号后的判断就不会执行了
|
1.单或,如果前后都是布尔型,有真则真,但是如果符号前为true,符号后的判断会继续执行
||
1.双或,有真则真,但是有短路效果,如果符号前为true,符号后的判断就不会执行了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class Demo02Logic { public static void main (String[] args) { int a = 10 ; int b = 20 ; boolean result01 = (++a<100 )||(++b>10 ); System.out.println("result01 = " + result01); System.out.println("a = " + a); System.out.println("b = " + b); } }
问题:定义一个变量(a),随意给一个值,判断这个变量接收的值是否在1-100之间
1<=a<=100 -> 错误,这是数学写法
i>=1 && i<=100 -> java写法,用逻辑运算符拼接多个判断
5.三元运算符 1 2 3 4 5 1. 格式: boolean 表达式?表达式1 :表达式2 2. 执行流程: 先判断,如果是true ,就走?后面的表达式1 ,否则就走:后面的表达式2
流程控制 键盘录入 1 2 3 4 5 6 7 8 9 10 11 12 13 1. 概述:是java定义好的一个类2. 作用:将数据通过键盘录入的形式放到代码中参与运行 3. 位置:java.util4. 使用: a.导包:通过导包找到要使用的类 -> 导包位置:类上 import java.util.Scanner -> 导入的是哪个包下的哪个类 b.创建对象 Scanner 变量名 = new Scanner (System.in); c.调用方法,实现键盘录入 变量名.nextInt() 输入整数int 型的 变量名.next() 输入字符串 String型的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 package com.msl.scnner;import java.util.Scanner;public class Demo01 { public static void main (String[] args) { Scanner sc = new Scanner (System.in); int data1 = sc.nextInt(); System.out.println("data1 = " + data1); String data2 = sc.next(); System.out.println("data2 = " + data2); } }
注意:
变量名.next():录入字符串 -> 遇到空格和回车就结束录入了
1 2 3 4 5 6 7 8 Exception in thread "main" java.util.InputMismatchException -> 输入类型不匹配异常 at java.base/java.util.Scanner.throwFor(Scanner.java:939 ) at java.base/java.util.Scanner.next(Scanner.java:1594 ) at java.base/java.util.Scanner.nextInt(Scanner.java:2258 ) at java.base/java.util.Scanner.nextInt(Scanner.java:2212 ) at com.atguigu.a_scanner.Demo04Scanner.main(Demo04Scanner.java:8 ) 原因:录入的数据和要求的数据类型不一致
Random随机数
学习Random和学习Scanner方式方法一样
1 2 3 4 5 6 7 8 9 1. 概述:java自带的一个类2. 作用:可以在指定的范围内随机一个整数3. 位置:java.util4. 使用: a.导包:import java.util.Random b.创建对象: Random 变量名 = new Random () c.调用方法,生成随机数: 变量名.nextInt() -> 在int 的取值范围内随机一个整数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package com.msl.random;import java.util.Random;public class Demo01 { public static void main (String[] args) { Random rd = new Random (); int data1 = rd.nextInt(100 ) + 1 ; System.out.println("data1 = " + data1); } }
1 2 3 4 5 6 7 在指定范围内随机一个数: nextInt(int bound) -> 在0 -(bound-1 ) a.nextInt(10 ) -> 0 -9 b.在1 -10 之间随机一个数: nextInt(10 )+1 -> (0 -9 )+1 -> 1 -10 c.在1 -100 之间随机一个数:nextInt(100 )+1 -> (0 -99 )+1 -> 1 -100 d.在100 -999 之间随机一个数: nextInt(900 )+100 -> (0 -899 )+100 -> 100 -999
switch(选择语句) 1.switch基本使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 1. 格式: switch (变量){ case 常量值1 : 执行语句1 ; break ; case 常量值2 : 执行语句2 ; break ; case 常量值3 : 执行语句3 ; break ; case 常量值4 : 执行语句4 ; break ; ... default : 执行语句n; break ; } 2. 执行流程: 用变量接收的值和下面case 后面的常量值匹配,匹配上哪个case 就执行哪个case 对应的执行语句 如果以上所有case 都没有匹配上,就走default 对应的执行语句n 3. break 关键字:代表的是结束switch 语句 4. 注意:switch 能匹配什么类型的数据: byte short int char 枚举类型 String类型
2.case的穿透性 1 1. 如果没有break ,就会出现case 的穿透性,程序就一直往下穿透执行,直到遇到了break 或者switch 代码执行完毕了,就停止了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 ```java public class Demo03Switch { public static void main (String[] args) { Scanner sc = new Scanner (System.in); int month = sc.nextInt(); switch (month){ case 12 : case 1 : case 2 : System.out.println("冬季" ); break ; case 3 : case 4 : case 5 : System.out.println("春季" ); break ; case 6 : case 7 : case 8 : System.out.println("夏季" ); break ; case 9 : case 10 : case 11 : System.out.println("秋季" ); break ; default : System.out.println("什么情况,你家有这个月份?" ); } } } ```
分支语句 if的三种格式 1 2 3 4 5 6 7 8 9 10 1. 格式: if (boolean 表达式){ 执行语句; } 2. 执行流程: 先走if 后面的boolean 表达式,如果是true ,就走if 后面大括号中的执行语句,否则就不走 3. 注意: if 后面跟的是boolean 表达式,只要是结果为boolean 型的,都可以放在小括号中,哪怕直接写一个true 或者false
1 2 3 4 5 6 7 8 9 1. 格式: if (boolean 表达式){ 执行语句1 ; }else { 执行语句2 ; } 2. 执行流程: a.先走if 后面的boolean 表达式,如果是true ,就走if 后面的执行语句1 b.否则就走else 后面的执行语句2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1. 格式: if (boolean 表达式){ 执行语句1 }else if (boolean 表达式){ 执行语句2 }else if (boolean 表达式){ 执行语句3 }...else { 执行语句n } 2. 执行流程: 从if 开始往下挨个判断,哪个if 判断结果为true ,就走哪个if 对应的执行语句,如果以上所有的判断都是false ,就走else 对应的执行语句n 3. 使用场景:2 种情况以上的判断
if和switch区别
switch和if的区别:debug
1.switch:会直接跳到相匹配的case
2.if:从上到下挨个判断 -> 实际开发主要用if做判断,灵活
循环语句
什么时候使用循环语句:
for循环 1 2 3 4 5 6 7 8 9 10 1. 格式: for (初始化变量;比较;步进表达式){ 循环语句 -> 哪段代码循环执行,就将哪段代码放到此处 } 2. 执行流程: a.先走初始化变量 b.比较,如果是true ,走循环语句,走步进表达式(初始化的变量的值进行变化) c.再比较,如果还是true ,继续走循环语句,走步进表达式 d.再比较,直到比较为false ,循环结束了
快捷键: 次数.fori
while循环 1 2 3 4 5 6 7 8 9 10 11 12 1. 格式: 初始化变量; while (比较){ 循环语句; 步进表达式 } 2. 执行流程: a.初始化变量 b.比较,如果是true ,就走循环语句,走步进表达式 c.再比较,如果还是true ,继续走循环语句,继续走步进表达式 d.再比较,直到比较为false ,循环结束
do…while循环 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1. 格式: 初始化变量; do { 循环语句; 步进表达式 }while (比较); 2. 执行流程: a.初始化变量 b.走循环语句 c.走步进表达式 d.判断,如果是true ,继续循环,直到比较为false ,循环结束 3. 特点: 至少循环一次
循环控制关键字 1 2 3 4 5 6 1. break : a.在switch 中代表结束switch 语句 b.在循环中代表结束循环 2. continue : 结束当前本次循环,直接进入下一次循环,直到条件为false 为止
死循环 1 2 3 4 5 1. 概述: 一直循环 2. 什么条件下一直循环: 比较条件一直是true
嵌套循环 1 2 3 1. 概述:循环中还有循环2. 执行流程: 先执行外层循环,再进入内层循环,内层循环就一直循环,直到内层循环结束,外层循环进入下一次循环,直到外层循环都结束了,整体结束
数组 数组的定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 1. 问题:想将一个数据保存起来,我们可以使用变量,但是变量一次只能存储一个数据,所以我们想能不能一次存多个数据 2. 数组概述:是一个容器,数组本身属于引用数据类型 3. 作用:一次存储多个数据 4. 特点: a.既可以存储基本类型的数据,还能存储引用类型的数据 b.定长(定义数组时长度为多长,最多就能存多少个数据) 5. 定义: a.动态初始化: 数据类型[] 数组名 = new 数据类型[长度] 数据类型 数组名[] = new 数据类型[长度] 各部分解释: 等号左边的数据类型:规定了数组中只能存储什么类型的元素 []:代表的是数组,一个[]代表一维数组,两个[][]代表二维数组 数组名:自己取的名字,遵循小驼峰 new :代表的是创建数组 等号右边的数据类型:要和等号左边的数据类型一致 [长度]:指定数组长度,规定了数组最多能存多少个数据 b.静态初始化 数据类型[] 数组名 = new 数据类型[]{元素1 ,元素2. ..} -> 不推荐使用 数据类型 数组名[] = new 数据类型[]{元素1 ,元素2. ..} -> 不推荐使用 c.简化的静态初始化: 数据类型[] 数组名 = {元素1 ,元素2. ..}-> 推荐使用 6. 区别: a.动态初始化:定义的时候只指定了长度,没有存具体的数据 当只知道长度,但不知道具体存啥数据时可以使用动态初始化 b.静态初始化:定义的时候就直接知道存啥了
索引 1 2 3 4 5 6 7 8 9 10 11 1. 概述:元素在数组中存储的位置 2. 特点: a.索引唯一 b.索引都是从0 开始的,最大索引是数组长度-1 3. 注意: 我们将来操作元素,必须通过索引来操作 存数据,要指定索引 取数据,要指定索引 查数据,要指定索引
数组的操作 存储元素 1 2 1. 格式: 数组名[索引值] = 值 -> 将等号右边的值放到数组指定的索引位置上
获取元素 1 2 3 4 5 6 7 8 9 10 11 1. 地址值: 数组在内存中的身份证号,唯一标识,我们可以通过这个唯一标识到内存中准确找到这个数,从而操作这个数组中的数据 2. 注意: a.直接输出数组名,会直接输出数组在内存中的地址值 b.如果数组中没有存元素,那么直接获取索引上对应的元素也是有值的,只不过不是我们存储的数据,而是数组中的元素默认值 整数: 0 小数: 0.0 字符: '\u0000' -> 空白字符 -> 对应的int 值是0 布尔: false 引用: null
遍历数组
1 2 3 for (int i : arr) { System.out.println(arr[i]); }
1 2 3 4 for (int i = 0 ; i < arr.length; i++) { System.out.println(arr[i]); }
异常操作
数组索引越界异常_ArrayIndexOutOfBoundsException
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class Demo09Array { public static void main (String[] args) { int [] arr = new int [3 ]; arr[0 ] = 100 ; arr[1 ] = 200 ; arr[2 ] = 300 ; for (int i = 0 ; i <= arr.length; i++) { System.out.println(arr[i]); } } }
空指针异常_NullPointerException
1 2 3 4 5 6 7 8 9 public class Demo10Array { public static void main (String[] args) { int [] arr = new int [3 ]; System.out.println(arr.length); arr = null ; System.out.println(arr.length); } }
内存图 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 1. 内存:可以理解"内存条" ,任何程序,软件运行起来都会在内存中运行,占用内存,在java的世界中,将内存分为了5 大块 2. 分为哪5 大块 栈(重点)(Stack) 主要运行方法,方法的运行都会去栈内存中运行,运行完毕之后,需要"弹栈" ,腾空间 堆(重点):(Heap) 每new 一次,都会在堆内存中开辟空间,并为此空间自动分配一个地址值 堆中的数据都是有默认值的 整数:0 小数:0.0 字符: '\u0000' 布尔:false 引用:null 方法区(重点)(Method Area) 代码的"预备区" ,记录了类的信息以及方法的信息 本地方法栈(了解):专门运行native 方法(本地方法) 本地方法可以理解为对java功能的扩充 有很多功能java语言实现不了,所以就需要依靠本地方法完成 寄存器(了解) -> 跟CPU有关
二维数组 二维数组的定义格式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 1. 概述:数组中的套多个数组2. 定义格式 a.动态初始化 数据类型[][] 数组名 = new 数据类型[m][n] -> 推荐 数据类型 数组名[][] = new 数据类型[m][n] 数据类型[] 数组名[] = new 数据类型[m][n] m:代表的是二维数组的长度 n:代表的是二维数组中每一个一维数组的长度 数据类型[][] 数组名 = new 数据类型[m][] -> 二维数组中的一维数组没有被创建 b.静态初始化 数据类型[][] 数组名 = new 数据类型[][]{{元素1 ,元素2. ..},{元素1 ,元素2. ..},{元素1 ,元素2. ..}} 数据类型 数组名[][] = new 数据类型[][]{{元素1 ,元素2. ..},{元素1 ,元素2. ..},{元素1 ,元素2. ..}} 数据类型[] 数组名[] = new 数据类型[][]{{元素1 ,元素2. ..},{元素1 ,元素2. ..},{元素1 ,元素2. ..}} c.简化静态初始化: 数据类型[][] 数组名 = {{元素1 ,元素2. ..},{元素1 ,元素2. ..},{元素1 ,元素2. ..}} 数据类型 数组名[][] = {{元素1 ,元素2. ..},{元素1 ,元素2. ..},{元素1 ,元素2. ..}} 数据类型[] 数组名[] = {{元素1 ,元素2. ..},{元素1 ,元素2. ..},{元素1 ,元素2. ..}}
动态初始化的二维数组,二维数组里面的一维数组长度是固定的
静态初始化的二维数组,二维数组里面的一维数组长度可以不固定
1 2 3 4 5 6 7 8 9 10 11 public class Demo01Array { public static void main (String[] args) { int [][] arr = new int [3 ][4 ]; int [][] arr2 = new int [3 ][]; System.out.println("===========================" ); int [][] arr3 = {{1 ,2 ,3 },{4 ,5 },{6 ,7 ,8 ,9 }}; } }
获取二维数组长度 1 2 3 4 1. 格式: 数组名.length 2. 获取每一个一维数组长度,需要先遍历二维数组,将每一个一维数组从二维数组中拿出来
获取二维数组中的元素 1 2 3 4 5 1. 格式: 数组名[i][j] i:代表的是一维数组在二维数组中的索引位置 j:代表的是元素在一维数组中的索引位置
1 2 3 4 5 6 7 8 public class Demo03Array { public static void main (String[] args) { String[][] arr = {{"张三" ,"李四" },{"王五" ,"赵六" ,"田七" },{"猪八" ,"牛九" }}; System.out.println(arr[0 ][0 ]); System.out.println(arr[2 ][0 ]); System.out.println(arr[1 ][1 ]); } }
二维数组中存储元素 1 2 3 4 5 1. 格式: 数组名[i][j] = 值 i:代表的是一维数组在二维数组中的索引位置 j:代表的是元素在一维数组中的索引位置
二维数组的遍历 1 2 1. 先遍历二维数组,将每一个一维数组遍历出来2. 再遍历每一个一维数组,将元素获取出来
方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1. 方法: 拥有功能性代码的代码块 将不同的功能放在不同的方法中,给每个方法取个名字,直接调用方法名,对应的方法就执行起来了,好维护 2. 通用定义格式: 修饰符 返回值类型 方法名(参数){ 方法体 return 结果 } 3. 通过通用格式,分成四种方法来学习: a.无参无返回值方法 b.有参无返回值方法 c.无参有返回值方法 d.有参有返回值方法
无参无返回值 1 2 3 4 5 6 7 8 9 10 11 12 13 14 1. 无参无返回值方法定义: public static void 方法名(){ 方法体 -> 实现此方法的具体代码 } 2. 调用:直接调用 在其他方法中: 方法名() 3. 注意事项: a.void 关键字代表无返回值,写了void ,就不要在方法中写return 结果 b.方法不调用不执行, main方法是jvm调用的 c.方法之间不能互相嵌套,方法之间是平级关系 d.方法的执行顺序只和调用顺序有关
有参数无返回值 1 2 3 4 5 6 7 1. 格式: public static void 方法名(数据类型 变量名){ 方法体 } 2. 调用: 直接调用:方法名(具体的值) -> 调用的时候要给参数赋值
无参有返回值 1 2 3 4 5 6 7 8 9 10 1. 格式: public static 返回值类型 方法名(){ 方法体 return 结果 } 2. 调用: 返回值返回给了谁? 哪里调用返回给哪里 a.打印调用:sout(方法名()) -> 不推荐使用 b.赋值调用:调用完之后用一个变量接收返回值结果 -> 极力推荐 数据类型 变量名 = 方法名()
有参有返回值 1 2 3 4 5 6 7 8 9 10 11 12 1. 格式: public static 返回值类型 方法名(参数){ 方法体 return 结果 } 2. 调用: a.打印调用: sout(方法名(具体的值)) b.赋值调用(极力推荐) 数据类型 变量名 = 方法名(具体的值)